

数据库基础(一)
进入小皮面板官网下载phpstudy
小皮面板(phpstudy) – 让天下没有难配的服务器环境!
安装phpstudy

启动apache和Mysql
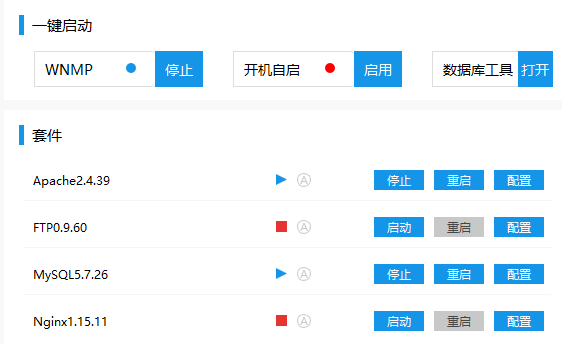
如有已被占用的端口,需要进入任务管理器把占用端口的进程结束
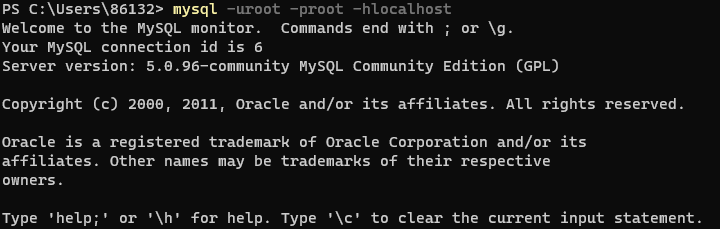
1、mysql的登陆与退出
mysql -uroot -proot -h127.0.0.1或-hlocalhost
mysql退出的三种方式
mysql> exit
mysql> quit
mysql> q
mysql注释符
1、#...
2、"-- ..."
3、/*...*/
mysql> use mysql;use用来选择数据库
mysql> show tables;查看当前数据库所有的表
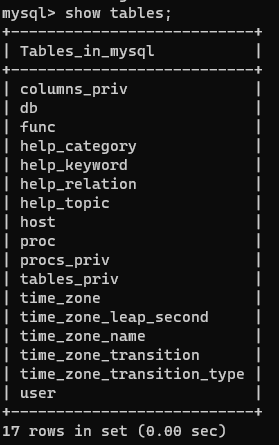
mysql> select * from user where user=’root’;
查看当前数据库里面的表 user 用户为root的密码
数据库的基本操作
1、新增数据库
create database database_name;
2、删除数据库
create database database_name;
3、改
create database database_name charset utf8
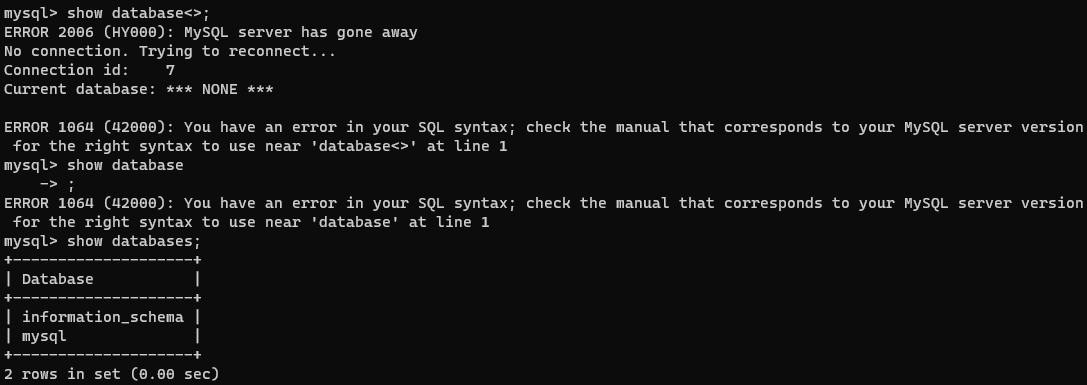
4、查看指定的数据库
show database; #查看所有数据库
设置默认的utf8,在配置文件中:写上character_set_server =utf8
show create database database_name;#查看指定数据库
show status;— 显示一些系统特定资源的信息,例如正在运行的线程数量
desc tabl_name;显示表结构、字段类型、主健,是否为空等属但不显示外键
mysql> show database;查看数据库
表的学习
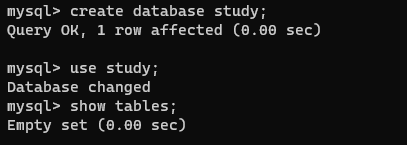
创建一个数据库,并且使用该数据库,查看数据库中的表,显示无表
1、查看表结构
desc table
describe table_name;
2、查看表都内容
select * from table_name;
3、建立表
Create table table_name (
属性名 数据类型 [约束条件];
属性名 数据类型 [约束条件];
....
属性名 数据类型 [约束条件];
);
例:
CREATE TABLE student (
s_id int(10) PRIMARY KEY NOT NULL,
s_name char(20) NOT NULL,
s_class varchar(20) NOT NULL
)ENGINE=InnoDB DEFAULT CHARSET=utf8;create database if not exists [table];
if not exists 表示当相同的表名存在时,则不执行此创造语句,避免语句执行错误
ENGINE设置表的引擎
DEFAULT CHARSET=utf8表示默认字符类型
常见的数据库引擎有InnoDB myisam
数据类型
MySQL支持多种数据类型和约束,以满足不同的需求。下面我将分别列出这些数据类型和约束,并简要说明它们的作用。
MySQL 数据类型
1. 数值类型
- TINYINT:非常小的整数,范围是 -128 到 127 或者 0 到 255(无符号)。
- SMALLINT:较小的整数,范围是 -32,768 到 32,767 或者 0 到 65,535(无符号)。
- MEDIUMINT:中等大小的整数,范围是 -8,388,608 到 8,388,607 或者 0 到 16,777,215(无符号)。
- INT/INTEGER:标准整数,范围是 -2,147,483,648 到 2,147,483,647 或者 0 到 4,294,967,295(无符号)。
- BIGINT:大的整数,范围是从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 或者 0 到 18,446,744,073,709,551,615(无符号)。
- FLOAT:单精度浮点数。
- DOUBLE:双精度浮点数。
- DECIMAL:固定点数。用于存储精确的小数数值。
2. 日期与时间类型
- DATE:日期值,格式为 ‘YYYY-MM-DD’。
- TIME:时间值或持续时间,格式为 ‘HH:MM:SS’。
- DATETIME:日期和时间组合,格式为 ‘YYYY-MM-DD HH:MM:SS’。
- TIMESTAMP:时间戳,记录从1970年1月1日午夜以来的秒数。
- YEAR:四位数表示的年份 (1901 to 2155)。
3. 字符串类型
- CHAR:固定长度字符串。最大长度为255个字符。
- VARCHAR:可变长度字符串。更灵活,适合存储长度变化的数据。
- TEXT:长文本数据。
- BLOB:用于存储大量的二进制数据。
- ENUM:枚举类型,只能选择列表中的一个值。
- SET:集合类型,可以保存多个预定义值之一。
MySQL 约束
约束用于确保表中的数据完整性。以下是常用的几种约束:
- NOT NULL:确保列不能包含NULL值。
- UNIQUE:保证该列的所有值都是唯一的。
- PRIMARY KEY:唯一标识表中的每一行的一个或一组字段。它必须是唯一的且不允许为空。
- FOREIGN KEY:用来建立和加强两个表数据之间的链接。
- CHECK:确保一列或多列的值满足特定条件。
- DEFAULT:当插入新记录时如果没有指定某个字段的值,则使用默认值填充。
- INDEX:创建索引以提高查询效率。这虽然不是严格意义上的“约束”,但对性能有重大影响。
修改表
1. 添加新列
要向已存在的表添加一个新的列,可以使用 ALTER TABLE 语句:
ALTER TABLE table_name ADD column_name datatype [constraints];- 示例:向
employees表中添加一列email类型为 VARCHAR(50)。
ALTER TABLE employees ADD email VARCHAR(50);2. 删除列
如果需要从表中移除某一列,同样使用 ALTER TABLE 语句:
ALTER TABLE table_name DROP COLUMN column_name;- 示例:从
employees表中删除email列。
ALTER TABLE employees DROP COLUMN email;3. 修改现有列
更改现有列的数据类型或约束条件也通过 ALTER TABLE 实现:
ALTER TABLE table_name MODIFY column_name new_datatype [new_constraints];- 示例:将
employees表中的email列的数据类型改为 TEXT。
ALTER TABLE employees MODIFY email TEXT;4. 重命名列
有时可能需要更改列的名字,这也可以通过 ALTER TABLE 来完成:
ALTER TABLE table_name CHANGE old_column_name new_column_name datatype [constraints];- 示例:将
employees表中的first_name列更名为fname。
ALTER TABLE employees CHANGE first_name fname VARCHAR(30);5. 增加约束
向表中添加主键、外键或其他类型的约束:
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint_type (column_name,...) [reference_definition];- 示例:为
orders表添加外键引用customers表的id字段。
ALTER TABLE orders ADD CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers(id);6. 删除约束
删除特定的约束:
ALTER TABLE table_name DROP CONSTRAINT constraint_name;- 注意:某些版本的 MySQL 可能要求指定约束的具体类型(如 PRIMARY KEY, FOREIGN KEY 等)。
- 示例:删除名为
fk_customer的外键。
ALTER TABLE orders DROP FOREIGN KEY fk_customer;查询表结构
查看当前表的定义信息,包括所有字段及其属性:
DESCRIBE table_name;
-- 或者
SHOW COLUMNS FROM table_name;在表中插入数据(创建数据 )
创建新记录通常通过 INSERT INTO 语句来完成。可以指定要插入到表中的具体字段值。
- 语法:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);- 示例:
假设有一个名为students的表,包含id,name, 和age三个字段。
INSERT INTO students (id, name, age)
VALUES (1, '张三', 20);- 注意事项:
- 确保值与列的数据类型匹配。
- 如果没有指定所有列,则未指定的列需要允许为NULL或者有默认值。
查询数据
查询表中的数据使用 SELECT 语句。可以通过条件筛选、排序等选项来定制查询结果。
- 语法:
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column ASC|DESC];- 示例:
从students表中选择年龄大于18岁的学生,并按年龄降序排列。
SELECT * FROM students
WHERE age > 18
ORDER BY age DESC;- 注意事项:
- 使用通配符
*可以选择所有列。 WHERE子句用于过滤记录。ORDER BY用来对结果集进行排序,默认为升序(ASC)。
- 使用通配符
更新数据
当需要修改已有记录时,可以使用 UPDATE 语句。
- 语法:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
[WHERE condition];- 示例:
更新students表中名字为“张三”的学生的年龄为21岁。
UPDATE students
SET age = 21
WHERE name = '张三';- 注意事项:
- 如果省略了
WHERE子句,所有的行都会被更新。 - 在执行此命令前确保已经备份重要数据或进行了适当的测试。
- 如果省略了
删除数据
删除表中的记录使用 DELETE 语句。同样地,也可以加上 WHERE 来限制哪些行被删除。
- 语法:
DELETE FROM table_name
[WHERE condition];- 示例:
从students表中删除名字为“李四”的学生。
DELETE FROM students
WHERE name = '李四';- 注意事项:
- 没有
WHERE子句会删除表内所有数据。 - 删除操作不可逆,请谨慎操作。
- 没有
查询操作
1. 基本查询
- 全表扫描:获取表中所有记录。
SELECT * FROM table_name;这条命令会返回 table_name 表中的所有列的所有行。
- 选择特定列:只选取需要的列。
SELECT column1, column2 FROM table_name;该语句仅显示指定的列(column1 和 column2)的数据。
2. 条件查询
- 使用 WHERE 子句过滤数据:
SELECT * FROM table_name WHERE condition;例如,查找年龄大于 20 的所有人:
SELECT * FROM persons WHERE age > 20;- 组合条件:使用 AND 或 OR 操作符。
SELECT * FROM table_name WHERE condition1 AND condition2;例子:
SELECT * FROM employees WHERE department = 'Sales' AND salary > 50000;3. 排序结果
- ORDER BY 子句:按一列或多列排序输出。
SELECT * FROM table_name ORDER BY column [ASC|DESC];例如,按薪水降序排列员工信息:
SELECT * FROM employees ORDER BY salary DESC;4. 分组与聚合
- GROUP BY 子句:用于结合聚集函数来计算分组后的统计值。
SELECT column, aggregate_function(column) FROM table_name GROUP BY column;例:计算每个部门的平均工资
SELECT department, AVG(salary) FROM employees GROUP BY department;- HAVING 子句:对分组后的结果进一步筛选。
SELECT column, aggregate_function(column) FROM table_name GROUP BY column HAVING condition;例:找出平均薪资超过 60,000 的部门
SELECT department, AVG(salary) FROM employees GROUP BY department HAVING AVG(salary) > 60000;5. 联合多个表
- INNER JOIN:返回两个表中匹配的行。
SELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column;例:假设我们有两个表 orders 和 customers,通过 customer_id 关联
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id;- LEFT JOIN / RIGHT JOIN:左连接或右连接可以保留左侧或右侧表中的所有记录,并在另一侧没有匹配时填充 NULL。
SELECT * FROM table1 LEFT JOIN table2 ON table1.column = table2.column;例子:
SELECT orders.order_id, customers.customer_name
FROM orders
LEFT JOIN customers ON orders.customer_id = customers.customer_id;- UNION:合并两个或更多 SELECT 语句的结果集。
(SELECT column FROM table1) UNION (SELECT column FROM table2);注意:两 SELECT 语句必须具有相同数量的列,并且对应列需具有相似的数据类型。
6. 子查询
- 单行子查询:作为表达式的一部分,在主查询之前执行。
SELECT column FROM table1 WHERE column = (SELECT column FROM table2 WHERE condition);例:找到与最高薪员工同名的所有员工
SELECT name FROM employees WHERE salary = (SELECT MAX(salary) FROM employees);- 多行子查询:当子查询可能返回多个结果时使用 IN, ANY, ALL 等运算符。
SELECT column FROM table1 WHERE column IN (SELECT column FROM table2 WHERE condition);例:列出所有位于有销售员的城市中的办公室
SELECT office_location FROM offices WHERE city IN (SELECT city FROM salesmen);连接
MySQL中的连接(JOIN)是一种用于从多个表中检索数据的强大工具。下面我将分别介绍左连接(LEFT JOIN)、右连接(RIGHT JOIN)、自连接(SELF JOIN),以及如何结合复杂查询和嵌套子查询来构造更强大的SQL语句。
1. 左连接 (LEFT JOIN)
左连接返回所有左侧表中的记录,即使在右侧表中没有匹配的记录。如果右侧表中没有找到匹配项,则结果集中对应于右侧表的部分将显示为NULL。
示例:
假设我们有两个表 employees 和 departments。每个员工属于一个部门。
employees表包含字段id,name,department_iddepartments表包含字段id,dept_name
SELECT e.name, d.dept_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.id;这条命令会列出所有员工的名字及其所属部门名称;对于那些不属于任何部门的员工,其部门名称将显示为NULL。
2. 右连接 (RIGHT JOIN)
右连接与左连接相反,它返回所有右侧表中的记录,即使左侧表中没有匹配的记录。若左侧表中找不到匹配,则结果集左侧部分的数据为NULL。
示例:
继续使用上面提到的两个表:
SELECT e.name, d.dept_name
FROM employees e
RIGHT JOIN departments d ON e.department_id = d.id;这将展示所有部门及对应的员工名。对于没有员工的部门,员工名将为空。
3. 自连接 (SELF JOIN)
自连接是指一张表与自身进行连接的情况,通常用来处理层次结构数据或比较同一表内不同行之间的关系。
示例:
假设有一个名为 managers 的表,其中包含经理与其上级经理的信息:
managers表包含字段id,name,superior_id
要找出每位经理的直接上级:
SELECT m1.name AS manager, m2.name AS superior
FROM managers m1
LEFT JOIN managers m2 ON m1.superior_id = m2.id;这里 m1 和 m2 都指向同一个表 managers,但代表不同的实例。
4. 结合复杂查询和嵌套子查询
当需要执行复杂的逻辑时,可以将多个查询组合起来,并且可以在查询中嵌入其他查询作为条件。
示例:
假设有三个表:orders, customers, products。我们需要找出购买了特定产品(例如 ID 为 5 的产品)的所有顾客信息,并计算他们各自对该产品的总消费金额。
orders包含order_id,customer_id,product_id,quantity,pricecustomers包含customer_id,name,emailproducts包含product_id,description
SELECT c.name, c.email, SUM(o.quantity * o.price) AS total_spent
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.product_id = (
SELECT product_id FROM products WHERE description = 'Product 5'
)
GROUP BY c.customer_id
HAVING total_spent > 100; -- 假设只关心那些花费超过100元的客户更新: 2025-04-11 20:58:26
原文: https://www.yuque.com/yuhui.net/network/cfecz12hti0xcylt
评论(0)
暂无评论